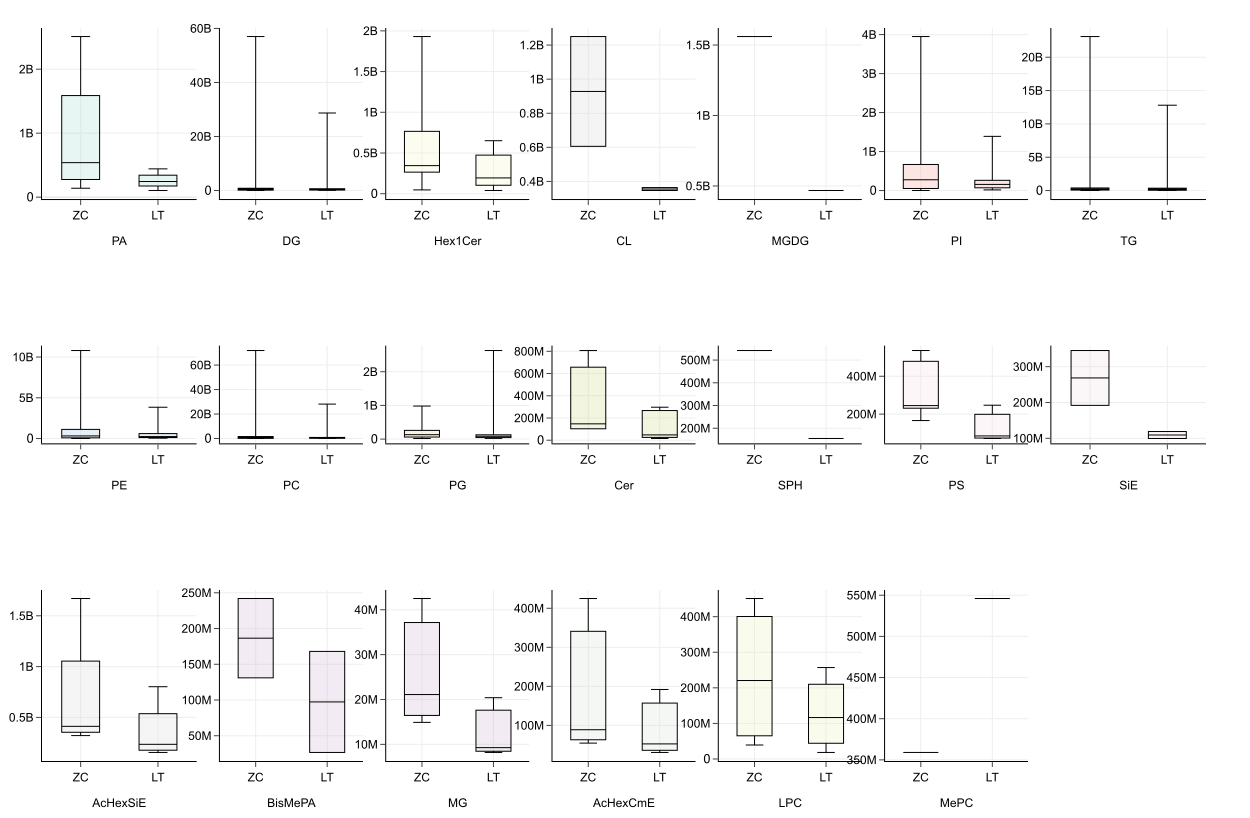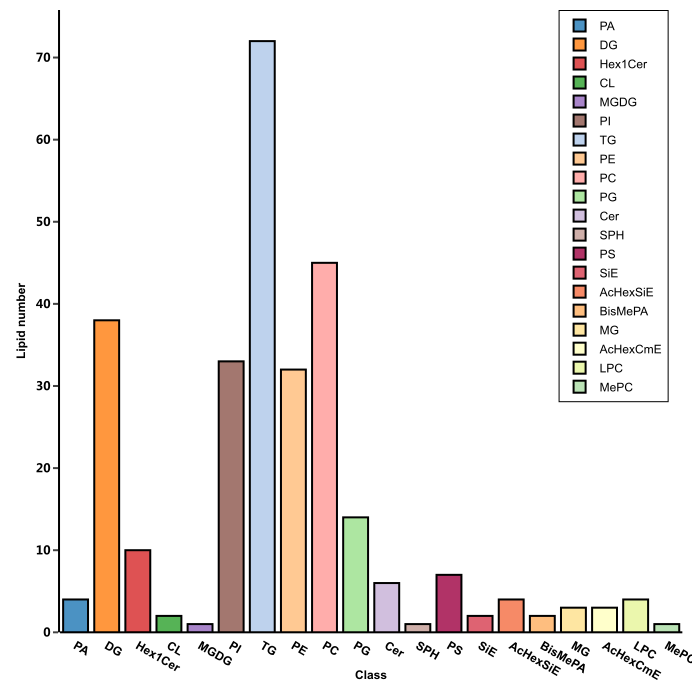
代谢组数据分析
代谢组学是一门对某一生物或细胞所有低分子质量代谢产物(以相对分子质量<1000的有机和无机的代谢物为研究核心区)进行分析的新兴学科。生物样本通过NMR、GC-MS、LC-MS等高通量仪器分析检测后,能产生大量的数据,这些数据具有高维,少样本、高噪声等复杂特征,同时代谢物多且代谢物之间联系密切,因此从复杂的代谢组学数据中确定与所研究的现象有关的代谢物,筛选出候选生物标记物成为代谢物组学研究的关键点。一般会对代谢组数据开展包括单变量分析、多变量分析(PCA等)、火山图,热图,KEGG等数据分析。
单变量 PCA (O)PLS-DA 脂质组
单变量分析方法仅分别分析单个变量,不考虑多个变量的相互作用与内在联系。具有简单性、易应用性和可解释性。但是无法基于整体数据对所测样品的优劣、差异进行综合评价和分析。差异倍数变化大小(Fold Change,FC)表示实验组与对照组的含量比值,可以快速考察各个代谢物在不同组别之间的含量变化大小。显著性检验p值即概率,反映某一事件发生的可能性大小,用于区分该变量是否具有统计显著性,通常认为p<0.05具有统计显著性。由于代谢组学的变量较多,必要时需要进行多重假设检验,对p值进行校正,降低假阳性。
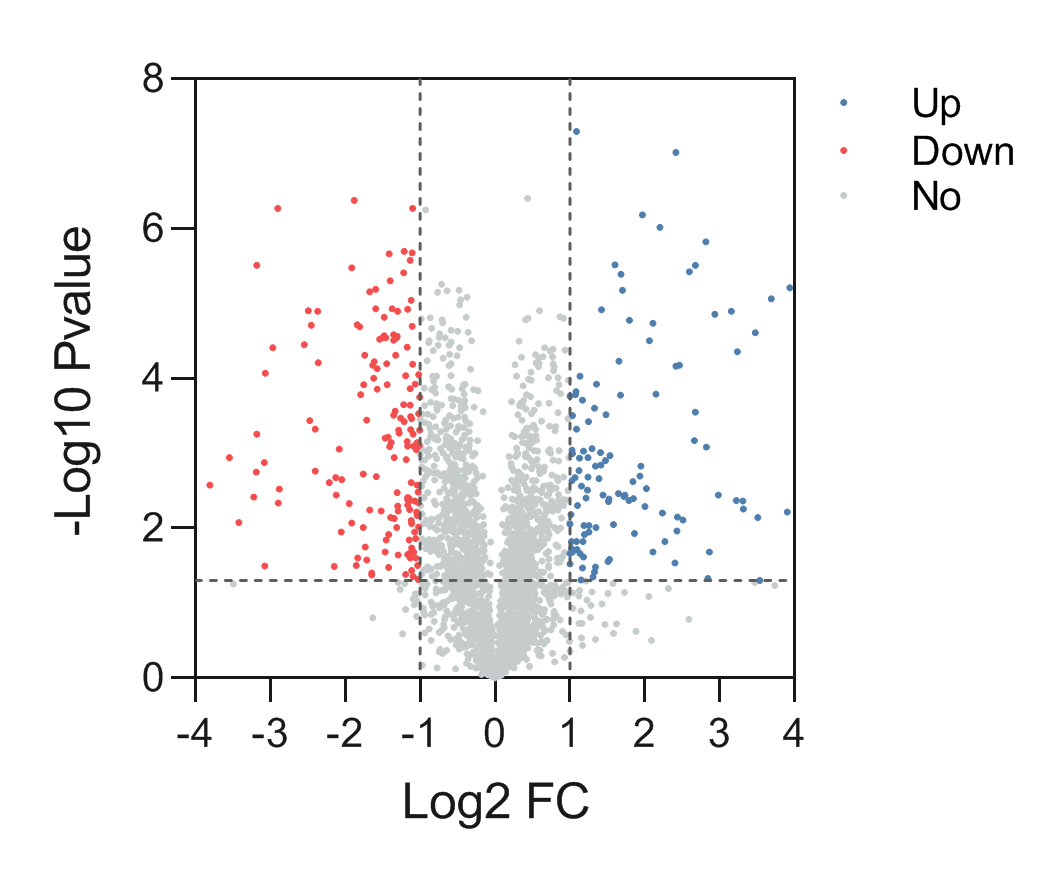
多变量分析方法能同时处理数百或数千个变量,并且能处理变量之间的相互关系。利用变量之间的协方差或相关性,使原始数据在较低维空间上的投影能尽可能地捕获数据中的信息。但是如果存在大量无信息变量可能会妨碍多变量分析的能力,无信息变量的数量越多,减少真阳性数量的效果就越显著。
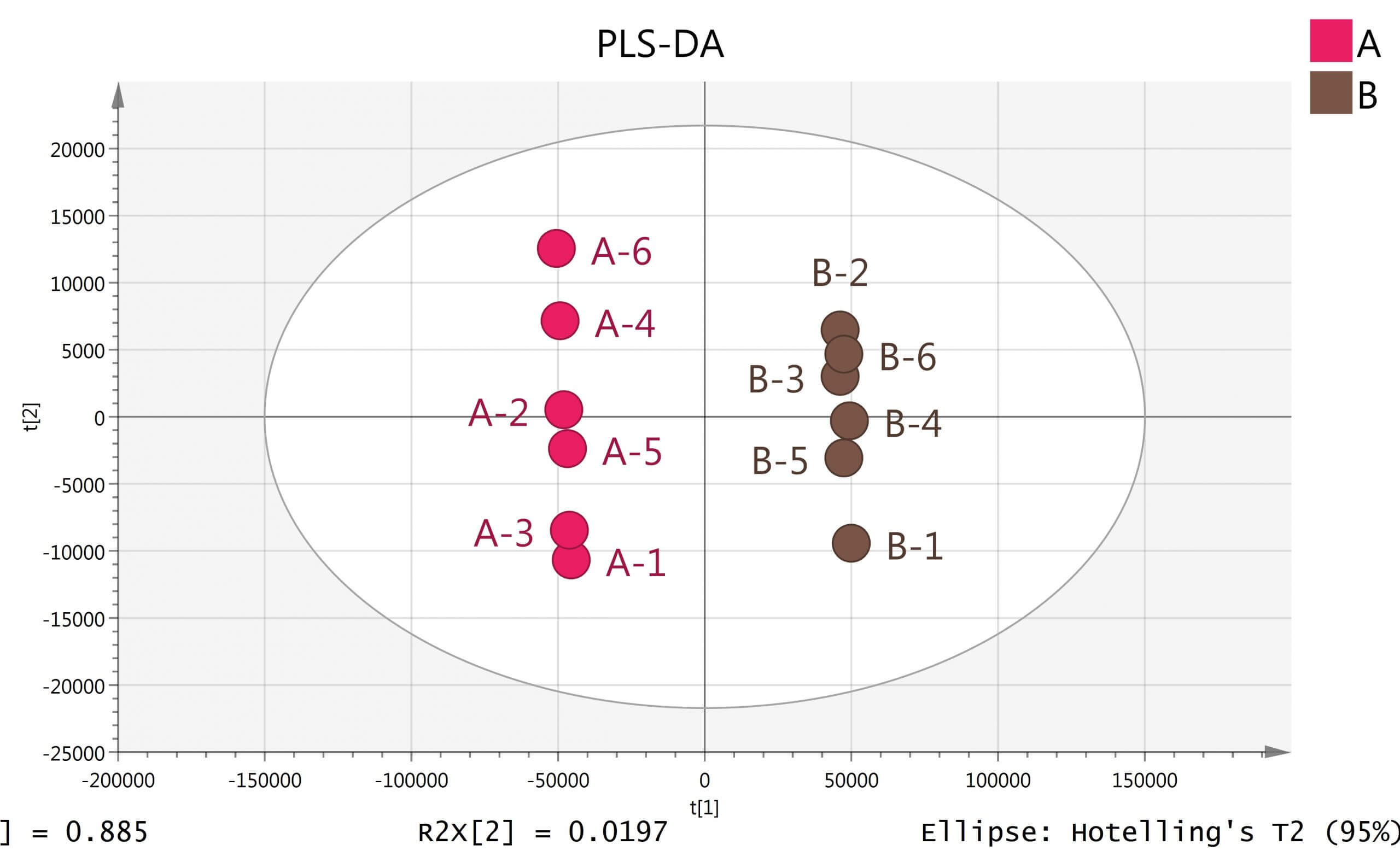
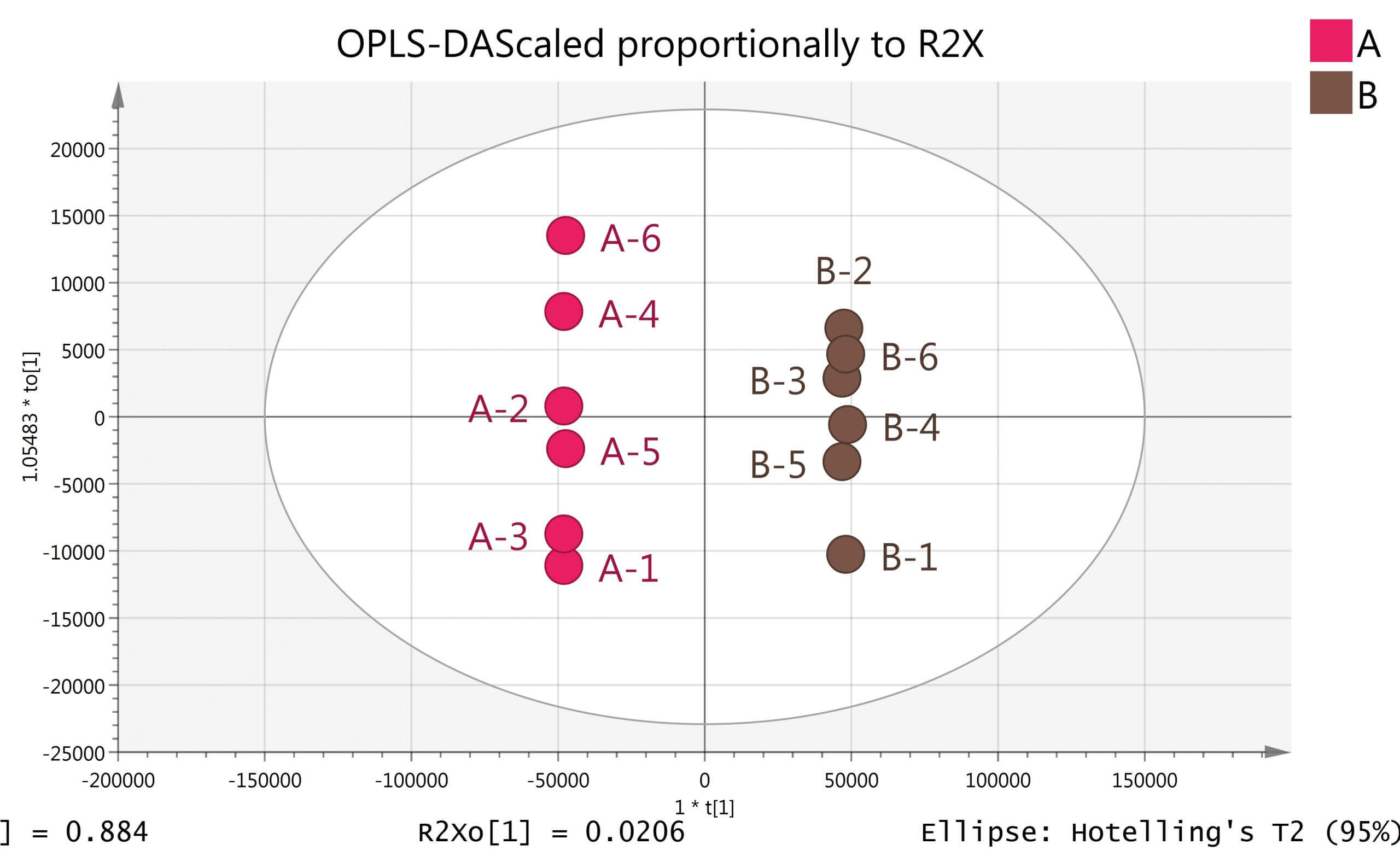
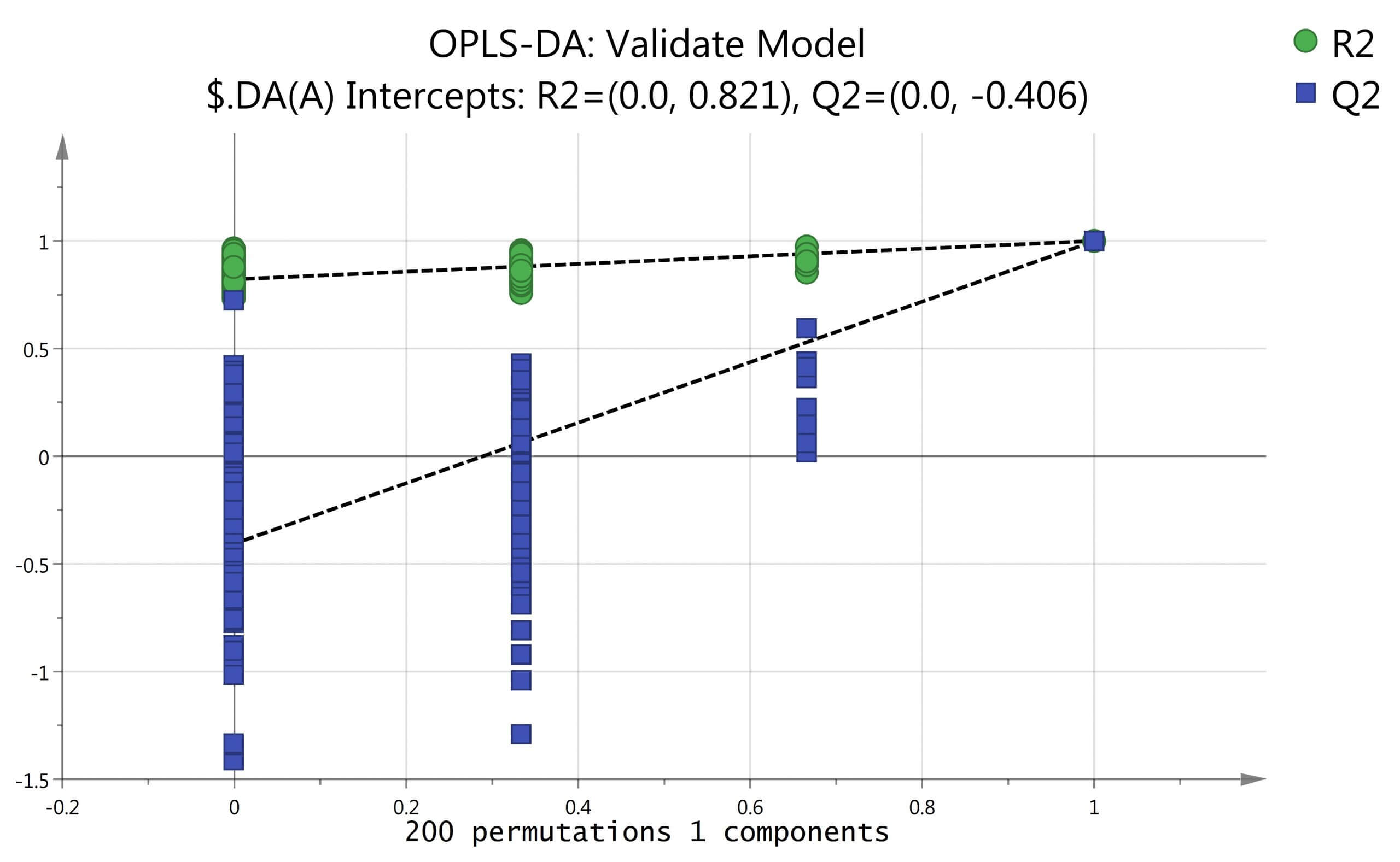
多变量分析分为无监督分析方法和有监督分析方法。在代谢组学分析中无监督学习有主成分分析(Principal Component Analysis,PCA),只需要数据集X,而有监督分析方法主要是偏最小二乘判别分析(Partial Least Squares Discrimination Analysis, PLS-DA)和正交偏最小二乘判别分析(Orthogonal Partial Least Squares Discrimination Analysis , OPLS-DA),这类方法在分析时除了需要数据集X,还需对样品进行指定并分组, 这样分组后模型将自动加上另外一个隐含的数据集Y,通常Y的赋值用-1/1或者0/1表示类别信息。
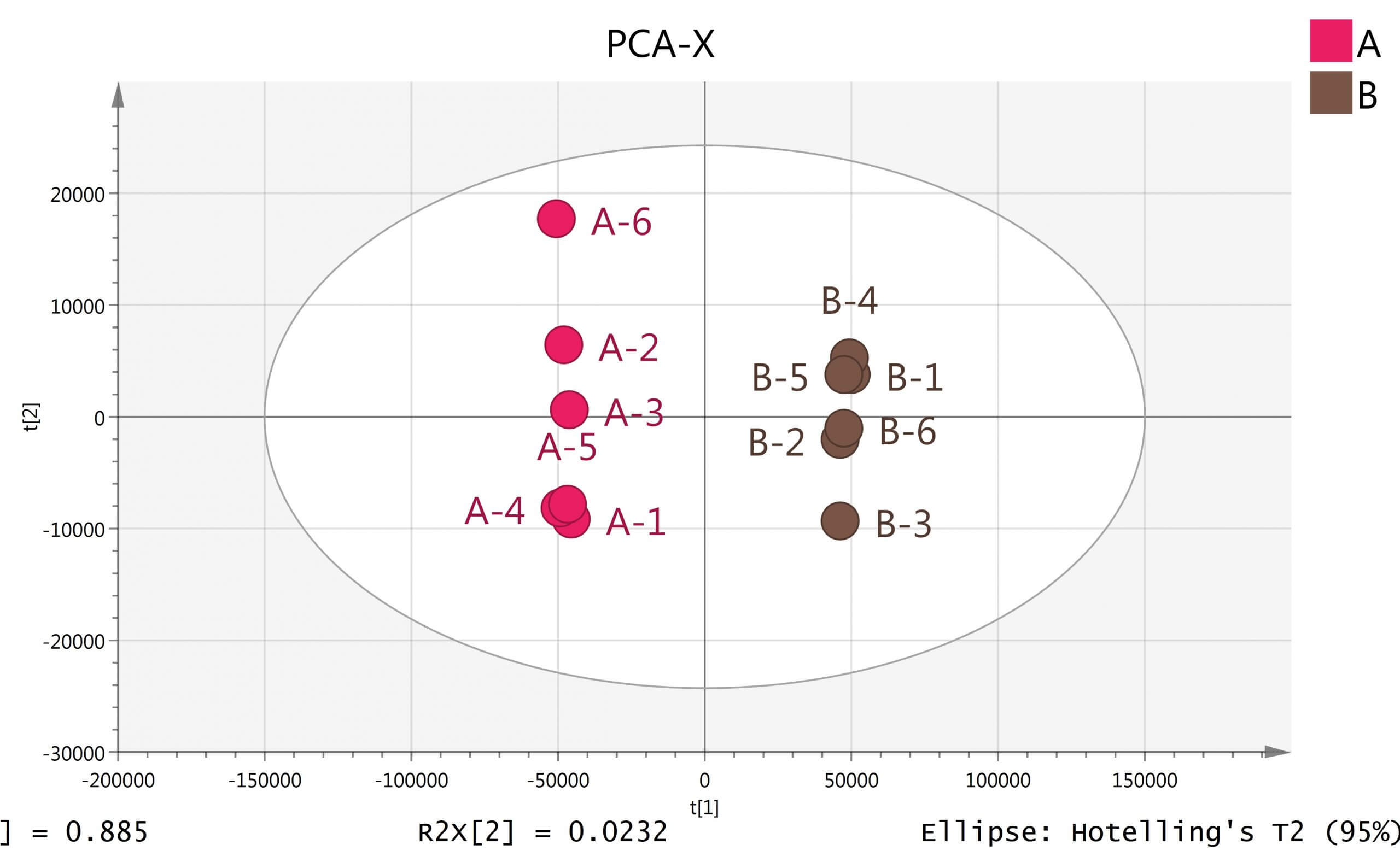
PCA是一种使用最广泛的数据降维算法,先找出数据X矩阵的方差最大方向作为PC1,在与PC1正交的平面中找出使得方差最大的作为PC2,依次类推。从而建立低维平面或空间 (通常2~5 维), 以此分析和概览整个数据集。PCA不是一种分类方法,但能提供对复杂数据集的直观解释,并从中揭示出数据集中观测数据的分组、趋势以及离群。对明显不同于大部分样品的离群样品,可加以甄别或剔除。另外,如果存在质控样品,PCA还可进行质控,如果质控样品很分散或具有一定的变化趋势,则说明检测质量存在一定的问题。
PCA分析主要是为了看数据的一个质量,也就是稳定性如何,QC样品如果比较集中,那么则反映数据的质量较好。另外可以直观的观察被分析样本有无天然的分组。